
Zero-Downtime Deployments in Healthcare: How We Design Systems That Never Go Offline

Robert Downey, Chief Technology Officer, Data Solutions Group at RLDatix
Somewhere in healthcare IT right now, a calendar invite is going out for a 2 a.m. maintenance window. Clinicians will lose access to patient charts and histories for a few hours while the system is down. Behind the scenes, an ops team will set an alarm, push a release, watch a dashboard, and hope nothing goes wrong before sunrise.
We treat this ritual as the cost of doing business, but it isn’t. In fact, scheduled downtime is rarely unavoidable. It’s the result of early architecture decisions that are difficult to roll back.
On the team behind VitalCenter Online (VCO), RLDatix’s SaaS platform for archiving legacy clinical and operational data, we made a difference choice. We run continuous, zero-downtime deployments across geographic production instances, so health systems can retire the source systems they were paying to keep alive.
The scale of data involved in this process is hard to picture. Our U.S. instance alone holds roughly 5 petabytes of data across more than 5,000 databases, hundreds of billions of documents and images, and serves hundreds of thousands of concurrent users — all live, all the time. And we deploy to these systems with no maintenance windows, no human intervention at release time and no interruption of service.
But the lesson here isn’t that our team works harder at 2 a.m. It’s that we decided, on day one, never to need 2 a.m. at all.
Zero-downtime is not a runbook. It’s a set of architectural commitments you make in the design phase and refuse to defer. Here are the four that matter most:
1. Design contracts to survive multiple versions running at once
The database gets most of the attention in conversations about zero-downtime deployment, but it is only one of the contracts in play. The UI calls the backend. Backend services call each other. Components communicate through message queues and event streams. During a rollout across a large fleet, none of those boundaries flip simultaneously.
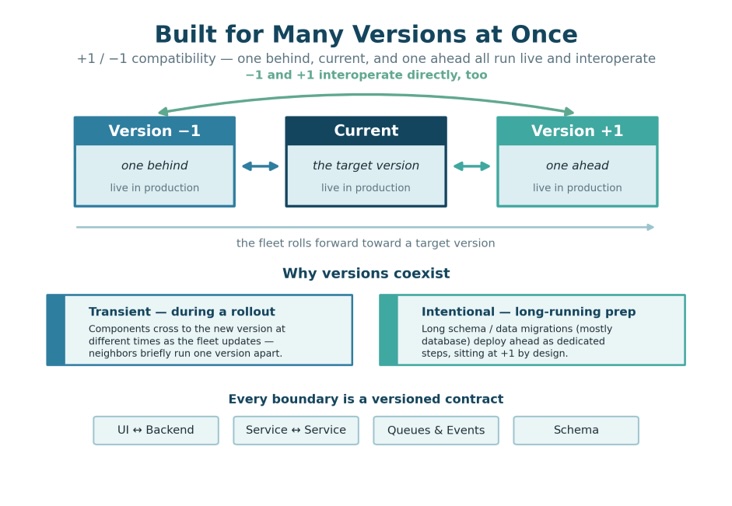
We design for that explicitly. Every component we ship must satisfy what we call +1/−1 compatibility: at any moment, three versions of a component — one behind current, current and one ahead — can run and communicate successfully. This is not a degraded state during a release. It is the default every component is built to honor.
In practice, that means a message produced by the previous version is readable by the next, and an API behaves correctly whether the component on the other end is one version back or one version forward. A change that cannot meet that bar does not ship.
Version gaps exist for two reasons. The first is transient: during a rollout, components on the same fleet upgrade at different times. The second is intentional: significant schema migrations run ahead of the main deployment as a deliberate prior step, leaving parts of the system one version ahead for a period.
In both cases, the rule is the same: every component must continue communicating with its one-behind and one-ahead neighbors, so those version gaps are never visible to a user.
In the database layer, this principle took us somewhere I’m genuinely proud of. We built a migration system that supports movement in both directions across every schema version ever shipped, back to the first version from 2015, with zero human intervention and zero downtime.
As a result, “roll back” stops being a fire drill and becomes a routine, automated capability. And because every intermediate schema state remains valid, going backward is as safe and predictable as going forward.
Finally, non-blocking operations complete the picture. A migration that requires a table lock is a maintenance window by another name. We avoid that entirely: changes are built in new tables, swapped in atomically, and high-availability secondaries absorb the load during the transition. The heavy work still happens but reads against live data never stop. The operation completes, and the clinician never feels it.
2. Earn your way to production through an unforgiving test gauntlet
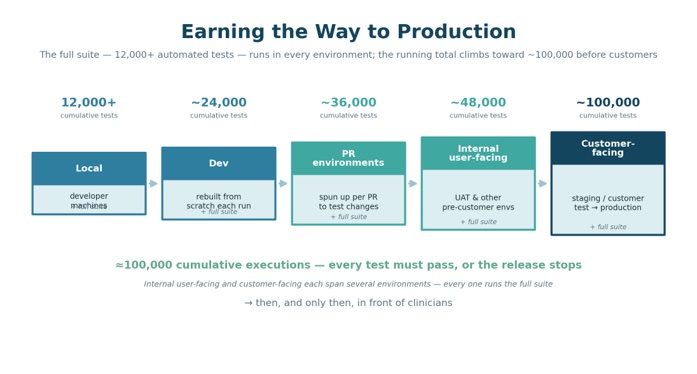
A change that behaves correctly on one database is not automatically safe on 5,000. With live regional instances standing in front of every customer, “we’ll watch it carefully in prod” is not a strategy. By the time a change reaches production, the margin for surprise has to be essentially gone.
That’s why we make changes earn their way forward. We maintain more than 12,000 automated tests across unit, integration, system and UI layers. The full suite runs at every environment a change passes through — not once at the end of the pipeline, but at each stop. It runs locally on developer machines, in a dev environment wiped and rebuilt from scratch on each run, in dedicated per-PR environments, in internal user-facing stages including UAT, and finally in customer-facing environments including staging and production. A single failure anywhere stops the release.
The rollout itself has three governing properties:
- It is fully automated: The continuous delivery pipeline runs deployments with no human in the loop at release time, and binaries reach runtime only through that pipeline. Human judgment happens earlier in code review and change control, not in a tense 2 a.m. console session.
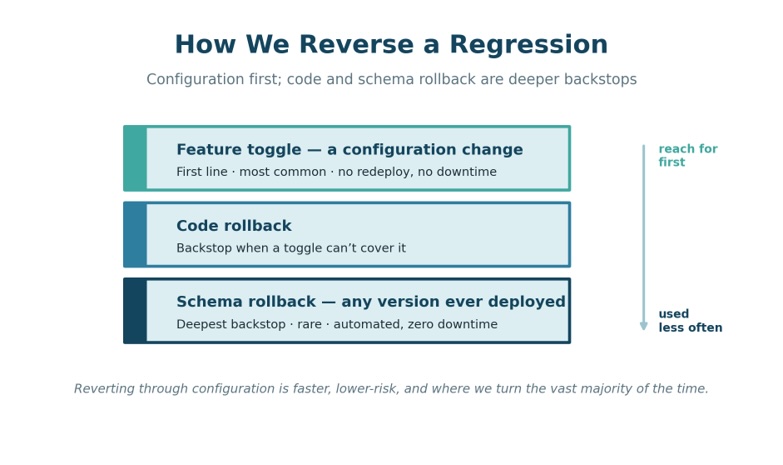
- It is staged: Changes move through a deliberate progression with no single moment where everything flips simultaneously. Each stage is a smaller, safer version of the next.
- It’s reversible by configuration: New functionality ships dormant behind feature toggles, is activated deliberately and can be deactivated without a redeploy or service interruption. Code and schema rollback exist as deeper backstops, but the toggle path is faster, lower risk and where the team turns first.
Once a change is live, centralized telemetry aggregates error rates, latency and functional health signals into a single view. Alerts surface anomalies within minutes, fast enough that a configuration change typically resolves the issue before a clinician notices anything.
3. Release small changes frequently
The safest release is the small one, and the only way to keep releases small is to ship them frequently.
The instinct in a high-stakes environment is to batch changes and release rarely. That feels like prudence. A release carrying a single day’s change has a small surface area: if something is off, the cause is usually obvious and the impact is contained. A release carrying months of accumulated work is a different problem, with dozens of interacting modifications landing at once and none easily isolated.
Instead, we release continuously, and we release often. Our target cadence is weekly to production. In practice it lands closer to twice a month, with customer-facing non-production environments updating multiple times a week. All of it happens without downtime or end-user impact.
Frequency is also a flywheel. Every uneventful release builds confidence, which sustains the cadence, keeps changes smal and makes the next release safer still. Teams that release rarely get worse at it. The process becomes fragile, fear accumulates, and deploy becomes a quarterly event everyone dreads, guaranteeing the changes are large and the risk is exactly what the process was meant to contain.
4. Make the decisions you can’t retrofit
Almost none of what is described above can be added to a system that was not built for it.
You cannot retrofit +1/−1 compatibility onto components that assumed everything upgrades simultaneously: that assumption is baked into thousands of interactions, and unpicking it is a rebuild, not a refactor. You cannot introduce bidirectional schema migrations into a database full of breaking changes. You cannot build a 100,000-execution test gauntlet on a codebase that was not written to be testable. You cannot bolt non-blocking database operations onto a data model that takes locks throughout. And feature toggles introduced late are not trustworthy, because the entire codebase has to honor them consistently for the guarantee to hold.
These are day-one decisions. We made a cloud-native platform with geo-redundant replication, an automated pipeline as the only route to production, +1/−1 versioning as a constraint every component must satisfy, feature toggles as a first-class part of how features are written, and bidirectional schema compatibility as an invariant no change is permitted to break.
The reason we can “do it live” today is simple: no one, years ago, chose the easy path with the intention of fixing it later. There is no “later.” Availability deferred at the design stage is availability you do not have in production.
The Cost of Downtime is Human Lives
It would be easy to read all of this as an engineering exercise, but I’d ask you to resist that framing, because it isn’t. The stakes aren’t technical. It’s human lives.
When a clinical system goes into a maintenance window, someone loses access to information a patient’s care depends on. A clinician opens an EMR and the record isn’t there. A medication history won’t load. A decision gets made with less context than it should have. We’ve normalized “the system is down for maintenance” to the point that we forget there’s a person on the other end of every minute of that downtime, often at the exact hours when staffing is thinnest and the stakes are highest.
The engineering described here exists so that VCO is simply there whenever care happens: at 2 a.m., mid-release, mid-migration, whenever a clinician needs a record.
The teams that operate live, mission-critical healthcare systems without maintenance windows did not get there through operational heroics. They got there by making a small number of non-negotiable decisions early and refusing to defer them, because the healthcare professionals relying on these systems deserve an architecture that never makes them wonder whether the record they need is available right now.
Frequently Asked Questions
A zero-downtime deployment lets software updates, database changes and new features go live without taking the system offline or interrupting users. Existing and updated components continue to operate together throughout the release, with no maintenance window and no service interruption.
VCO uses backwards and forwards version compatibility, automated testing across multiple staged environments, feature toggles, a fully automated deployment pipeline and non-blocking database migrations. These allow different software versions to run together during a rollout and enable changes to be reversed quickly if an issue occurs, usually through a configuration change rather than a code rollback.
Clinicians need access to patient records, medication histories and clinical data at any time, including overnight, on weekends and during shift handovers. Planned maintenance windows create gaps in that access at the exact hours when staffing is thinnest. Removing them means the system is available whenever care happens.
Some practices, such as feature toggles and improved monitoring, can be introduced into an existing system with reasonable effort. The practices that matter most, including version compatibility across component boundaries, bidirectional database migrations and a fully automated deployment pipeline, are much harder to retrofit. They are most effective when treated as architectural requirements from the start of a project.

Recommended
Other resources you might like